We only learn from error. The same could be said for neural networks.
I implemented a vision-language-action model trained to follow faces in its viewport, using pan/tilt servos to direct its view. I used a behavioral cloning approach: an oracle tracked the position of the face it was told to follow, and the VLA was trained to imitate the oracle's movement in each frame.
The initial sim environment consisted of slowly moving face images. These were followed by the oracle node, which knew the positions, but recorded the "correct" movements to make to follow them.

It's so... beautiful...
I recorded 10,000 episodes of various scenarios. Each scenario selected from about 500 face models that were AI-generated, some of which included specific attributes like glasses or hats. The movement patterns varied by scenario. Language command ranged from "track the person" for a single face, to "track the face with glasses" and "look at the right-most person" for multiple-face scenarios.
The VLA model was a ~1.5M parameter action model on top of a frozen CLIP text encoder and DINOv2 visual features.
I started with a hyperparameter sweep over 1,500 episodes. The results speak for themselves:

Not impressive stuff! It had an average error of about 20 degrees for basic scenarios -- in a field of view of just 60 degrees!
One issue stood out: the VLA was often several degrees away from its face target. However, the oracle was almost always directly on its target. Only 3% of the training data's frames had significant errors -- and these were exclusively during the first 3 to 5 frames of each episode. This was because at the beginning of each episode, the oracle started at a random position relative to the face. However, within a few frames, it had reached its target. From then on, it only moved slightly to keep up with the face as it moved.
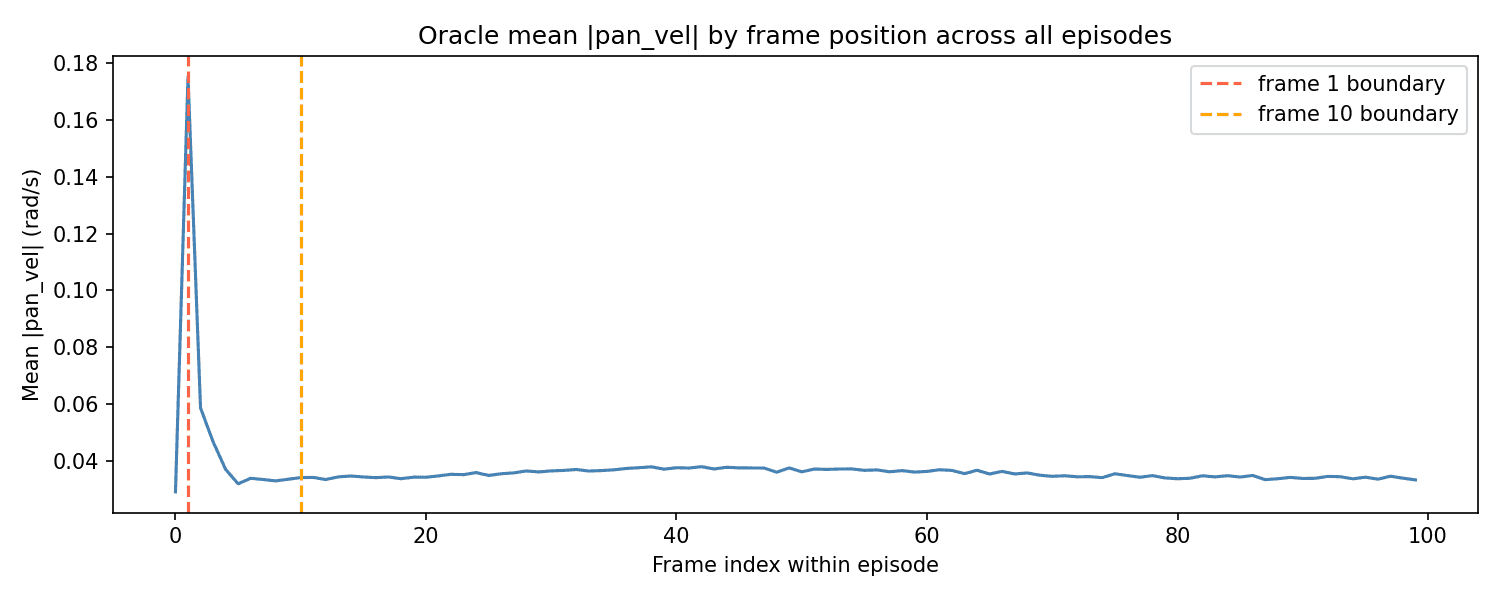 Average oracle pan velocity per frame, where 0 is the first frame of the episode.
Average oracle pan velocity per frame, where 0 is the first frame of the episode.
The result: only ~3% of the frames in the dataset were relevant to the VLA's most common situation, where the face is far from the VLA's frame center. The other 97% of training frames reflected a state rarely seen by the VLA, where the face was in the very middle of the viewport.
How to solve this? We could scale: with 30x more simulated episodes in the dataset, we'd have 30x the initial, high-error frames!
Or, we could add error by perturbing the target throughout each episode.
I added periodic disturbances: every few frames, the target face teleports to a random offset, forcing the oracle to recover multiple times in each episode and greatly increasing the amount of large-error samples.

I then ran another experiment of 1,500 episodes with the same hyperparameters.
The result was a model averaging less than 5 degrees error, a major improvement from the previous run:

The lesson? VLAs learn from error, like we do. Perfect, simple training scenarios will create models which can't handle imperfect, complex reality.